Semantic web is getting more and more important. It’s not just another buzzword. Semantic web allows data to be
shared and reused across application, enterprise, and community boundaries [1]. One of benefits is that web pages
with a clear semantic structure are more understandable for search engines.
If a website should be semantic then its source code (HTML) has to be semantic. HTML5 semantic elements
aren’t good enough because they are too general. So let’s extend HTML5. We have a few choices here –
RDFa and some microformats.
One of microformats is Microdata. Microdata is actually a set of HTML
attributes and elements used to describe meaning of web page content.
I’ll illustrate how simply it can be used.
Why I chose Microdata? I think it has simpler syntax than RDFa and because of schema.org (I’ll explain later in the article).
Example of turning non-semantic HTML into semantic HTML
Three months ago I’ve chosen a
REST
architecture for designing my new project at work. The project goal is to create
API for managing gyms,
trainings and trainees.
This article is just light intro to the REST world, don’t expect cool tips &
tricks (maybe in next article).
HTTP request methods
REST without using proper HTTP methods is a nonsense. There are about 9
methods but we need only 4.
POST – create a new resource
GET – get resource data
PUT – update a resource
DELETE – delete a resource
There is also PATCH method which is very similar to PUT method.
In fact PUT should rewrite a whole resource and PATCH only update
some attributes of a resource. More about PUT vs PATCHhere.
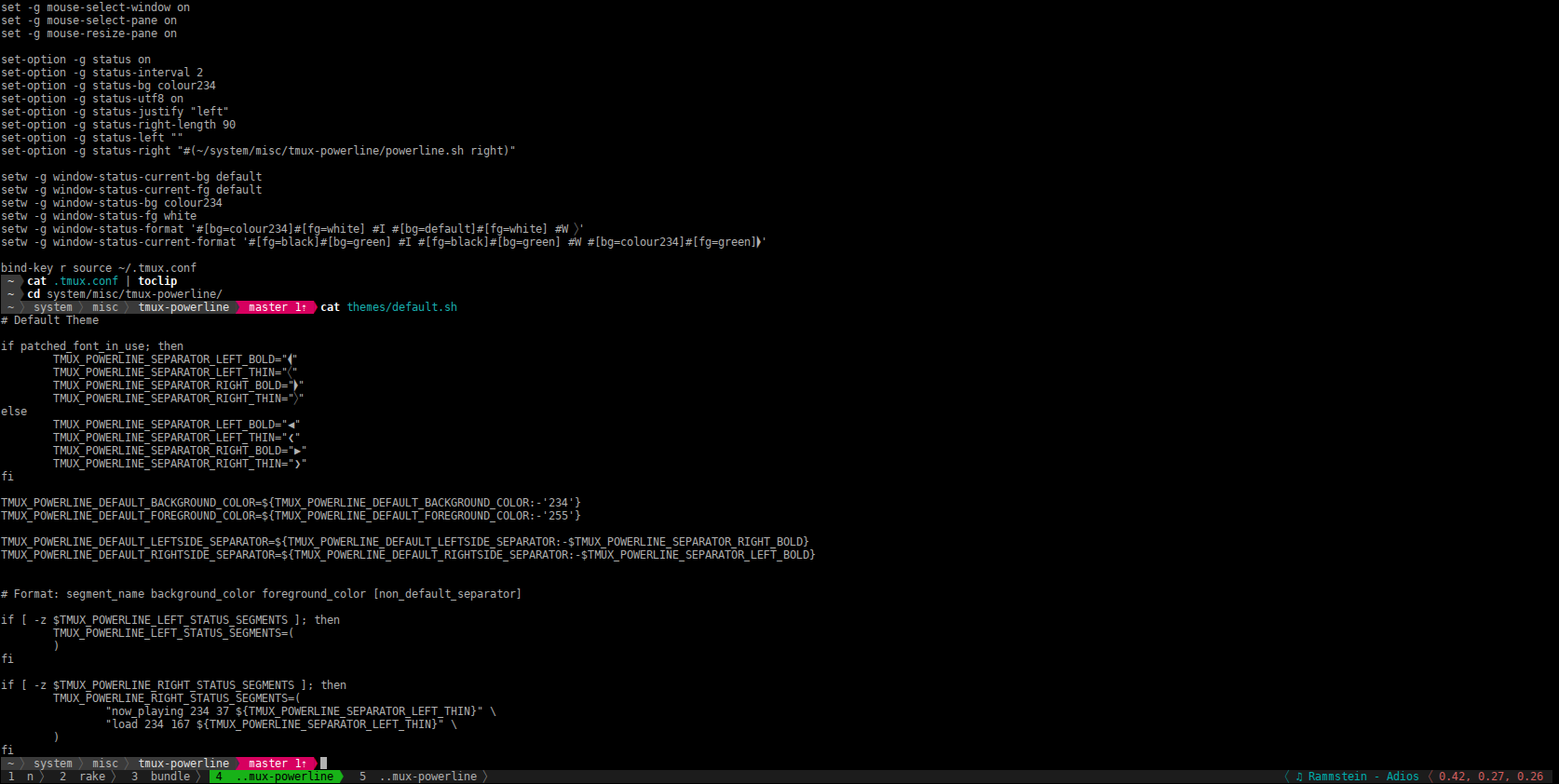
I’ve always wanted a sexy terminal prompt (aka $PS1, dear power users).
Finally I managed to find it. It’s called
powerline-shell. Except nice
look it offers git/svn/hg integration as you can see on the screenshot below.
It’s compatible with Bash, Zsh and Fish shells. Installation instructions are on
the Github project page.
I’m a content Chromium user. One of the most used functions I use every day is
searching from address bar (aka omnibox). You know, start writing site’s name,
press tab and type search query. How to make this working on your site? Just two things.
So, we have secure remote incremental backup solution
here. What about data
saved on our backup media (server)? I use dm-crypt – the standard device-mapper
encryption functionality provided by the Linux kernel. I’ve encrypted my backup
partition with an image from my gallery located on my work machine
(passphrases could be weak). Learn more about encrypting partitions with a key
here.
What I need to do before every backup process is to open the encrypted
partition. Obviously, after the backup process I close it.
Create encrypted partition
First modprobe kernel module: modprobe dm_mod.
We need to create encrypted partition for our sensitive data. Assuming we
already have a spare partition you can simply run the command:
copy the secret key file to user’s home directory. I prefer well-known images
which you can find easily on the Internet. If you lose your key file, you
won’t be able to decrypt your encrypted partition.
run script over SSH (using an pubkey for verification)
assuming the remote user is properly configured in sudoers file to run
cryptsetup; open an encrypted device
/dev/<path-to-encrypted-partition> (for example /dev/sda9) and call it
for example “no_more_secrets” (name-of-open-partition). Use copied keyfile as a key.
right after opening the encrypted device be sure
to remove the secret keyfile (shred command).
if opening the partition for the first time, you need to format it. Of course, you can choose
another filesystem.
mount “no_more_secrets” device. This step require adding a similar line to
/etc/fstab:
/dev/mapper/<name-of-open-partition> /mnt/somewhere ext4 rw,relatime,data=ordered,barrier=0,user,exec,suid,dev,noauto 0 0
All right, now we can access the encrypted partition, read & write data,
whatever.
To sum up, there are two different paths to the encrypted devices. First, e.g.
/dev/sda9 (path-to-encrypted-partition) is used only for “luksOpen” operation.
Opened device is located in /dev/mapper/ directory. This path is in the
script above used for mount, umount and mkfs.
Connect to Jabber. With XMPP4R, a library for
Ruby, it is possible, but not as easy as you could think.
One could ask “Why don’t you use
xmpp4r-simple?”. My answer: “I’m not a
pussy!”.
There are many little bastards you should know before fetching client’s
roster with contacts’ vcard (nickname, full name, avatar, …), status (online,
away, …) or status message. This is how I do this task. It works flawlessly.
This is simplified code I use in my chat application. Reading comments might be
helpful.
# Enable to see requests and responses between your machine and your jabber # server (easy to read XML). Recommended.Jabber::debug=true# first, sign in to your jabber account with your Jabber ID and passwordclient=Jabber::Client.new("someuser@somejabberserver.tld")client.connect()client.auth("my password")# now we are authenticated, let's fetch roster with all information we want# initialize rosterroster=Jabber::Roster::Helper.new(client)# request roster from jabber server, wait for responseroster.get_roster()roster.wait_for_roster()# now we know your friends' Jabber Idsroster.items.eachdo|jid,contact|puts"In roster I have: "+jidend# we don't know their status and status message, let's do it# First, add presence callback. If anyone in roster change his/her state # (e.g. come online), you will know it.roster.add_presence_callbackdo|roster_item,old_presence,new_presence|puts"Somebody changed his/her state to "+new_presence.status.to_s# new_presence also offers status message and other stuffend# To start receiving presence messages from your jabber server, you have to # send your presence first. It's really important to send your presence # AFTER roster.add_presence_callback, because the callback will not catch # every presence message which your jabber server sent to you.client.send(Jabber::Presence.new.set_type(:available))# Now you know who is online in your roster. If somebody from your # roster won't be caught in roster.add_presence_callback block, then # it just means he/she is offline.# get vcardroster.items.eachdo|jid,contact|# According to documentation, fetching vcard can take longer time.# Use threads if you think it is a good idea.Thread.newdovcard=Jabber::Vcard::Helper.get(client,jid)nickname=vcard&&vcard["FN"]||''#get avatar or other information hereendend
What I’ve learned from using XMPP4R library in my project – callbacks are good
thing and use them.
The default Rails logger is really messy. Write somewhere logger.debug
some_object.inspect and then for an hour search where the goddamn message is
in a log file. Fortunately we can format and colorize logger output.
Create config/initializers/log_formatting.rb file and paste this code:
Sometimes the default light gray placeholder color isn’t suitable for our needs.
It is really easy to fix it, however the workaround doesn’t work with Opera (but
who cares, Opera’s burying Presto and moving to Webkit) and Internet Explorer <
10.
Rsync is an ultimate tool for backup purposes. It offers transmitting data
remotely and securely over SSH. Also, it offers --link-dest option which
guarantees files are not duplicated in a filesystem thanks to hard links.
By the way, the same way it does proprietary Apple Time Machine.
Start writing a script
Sure, we will use many more other useful options, not just --link-dest. Here’s a simplified version of my
backup script:
 Example of a curriculum vitae header
Example of a curriculum vitae header With Microdata attributes
With Microdata attributes